While deep learning models have shown remarkable performance in various tasks, they are susceptible to learning non-generalizable spurious features rather than the core features that are genuinely correlated to the true label. In this paper, beyond existing analyses of linear models, we theoretically examine the learning process of a two-layer nonlinear convolutional neural network in the presence of spurious features. Our analysis suggests that imbalanced data groups and easily learnable spurious features can lead to the dominance of spurious features during the learning process. In light of this, we propose a new training algorithm called PDE that efficiently enhances the model's robustness for a better worst-group performance. PDE begins with a group-balanced subset of training data and progressively expands it to facilitate the learning of the core features. Experiments on synthetic and real-world benchmark datasets confirm the superior performance of our method on models such as ResNets and Transformers. On average, our method achieves a 2.8% improvement in worst-group accuracy compared with the state-of-the-art method, while enjoying up to 10x faster training efficiency.
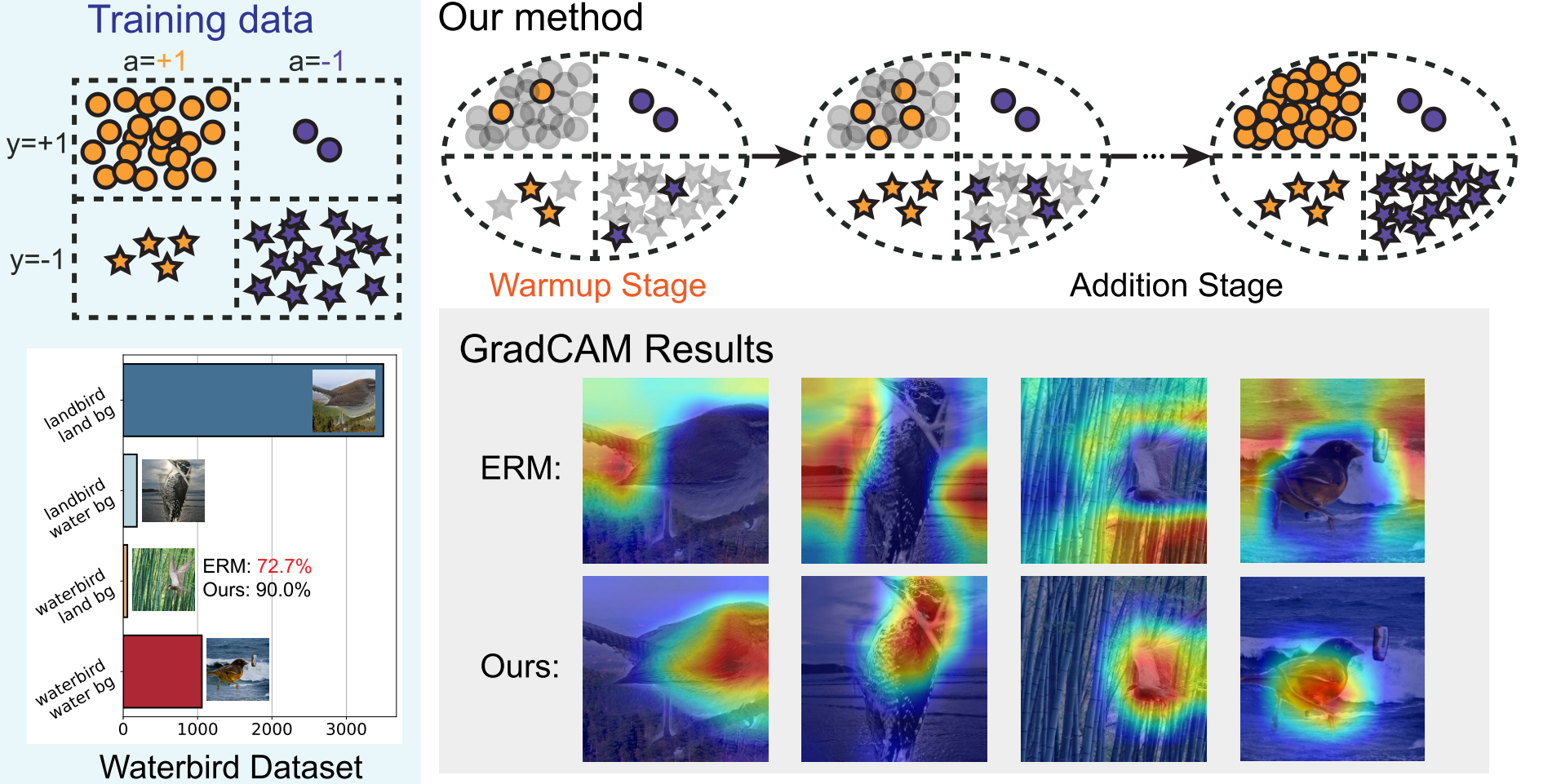
PDE is a two-stage training algorithm consisting of (1) warm-up and (2) expansion stages. In warm-up stage, we create a fully balanced dataset, in which each group is randomly subsampled to match the size of the smallest group, and consider it as a warm-up dataset. We train the model on the warm-up dataset for a fixed number of epochs. In the expansion stage, we proceed to train the model by incrementally incorporating new data into the training dataset. Practically, we consider randomly selecting m new examples for expansion every J epochs by attempting to draw a similar number of examples from each group. During the last few epochs of the expansion stage, we expect the newly incorporated data exclusively from the larger group, as the smaller groups have been entirely integrated into the warm-up dataset.
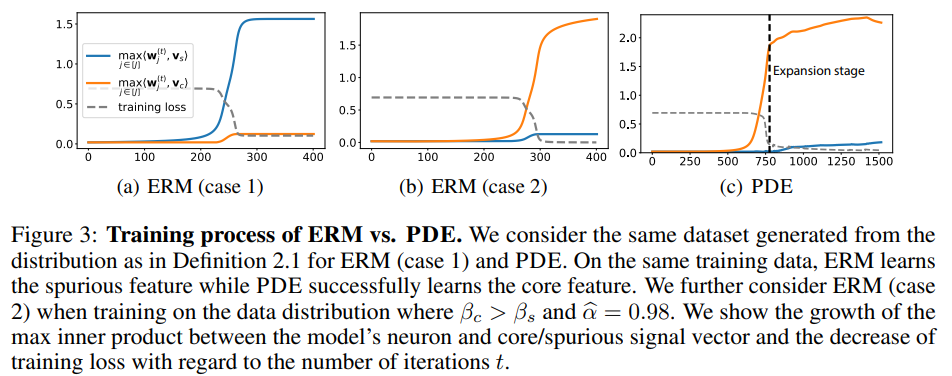
We consider the two cases in our theory. ERM, whether trained with GD or GD+M, is unable to accurately predict the small group in our specified data distribution for case 1. Confirming our theory, it rapidly learns the spurious feature as it minimizes the training loss, while barely learning the core feature. In contrast, PDE significantly improves worst-group accuracy while maintaining overall test accuracy comparable to ERM. PDE allows the model to initially learn the core feature using the warm-up dataset and continue learning when incorporating new data. Lastly, for case 2, we confirm that the learning of ERM is successful when the data distribution breaks the conditions of our theory: ERM correctly learns the core feature despite the imbalanced group sizes.
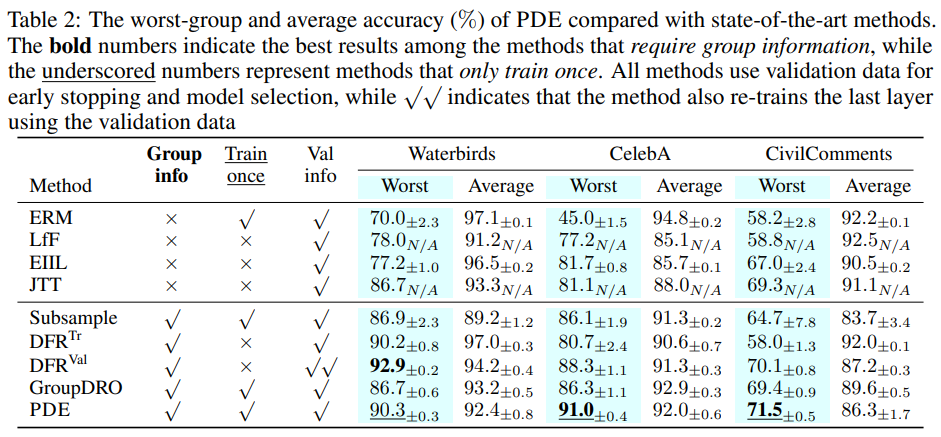
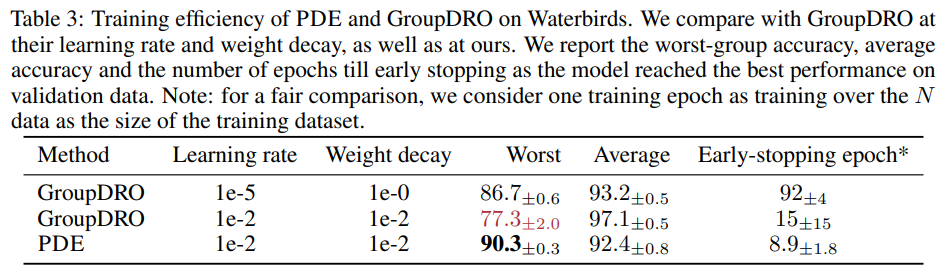
We conduct experiments on real benchmark datasets to (1) compare our approach with state-of-the-art methods, highlighting its superior performance and efficiency, and (2) offer insights into the design of our method through ablation studies. Importantly, we emphasize the comparison with GroupDRO, as it represents the best-performing method that utilizes group information. As shown in Table 2, PDE considerably enhances the worst-performing group's performance across all datasets, while maintaining the average accuracy comparable to GroupDRO. Considering all methods that only use validation data for model selection, GroupDRO still occasionally fails to surpass other methods. Remarkably, PDE's performance consistently exceeds them in worst-group accuracy. Furthermore, our method is more efficient as it does not train a model twice (as in JTT) and more importantly avoids the necessity for a small learning rate (as in GroupDRO). GroupDRO trained faster than the default results in significantly poorer performance similar to ERM. Conversely, PDE can be trained to converge rapidly on the warm-up set and reaches better worst-group accuracy 10x faster than GroupDRO at default. Note that methods which only finetune the last layer (DFR) are also efficient. However, they still require training a model first using ERM on the entire training data till convergence. In contrast, PDE does not require further finetuning of the model.
@inproceedings{robust2023deng,
title={Robust Learning with Progressive Data Expansion Against Spurious Correlation},
author={Deng, Yihe and Yang, Yu and Mirzasoleiman, Baharan and Gu, Quanquan},
booktitle={Advances in Neural Information Processing Systems},
year={2023}
}