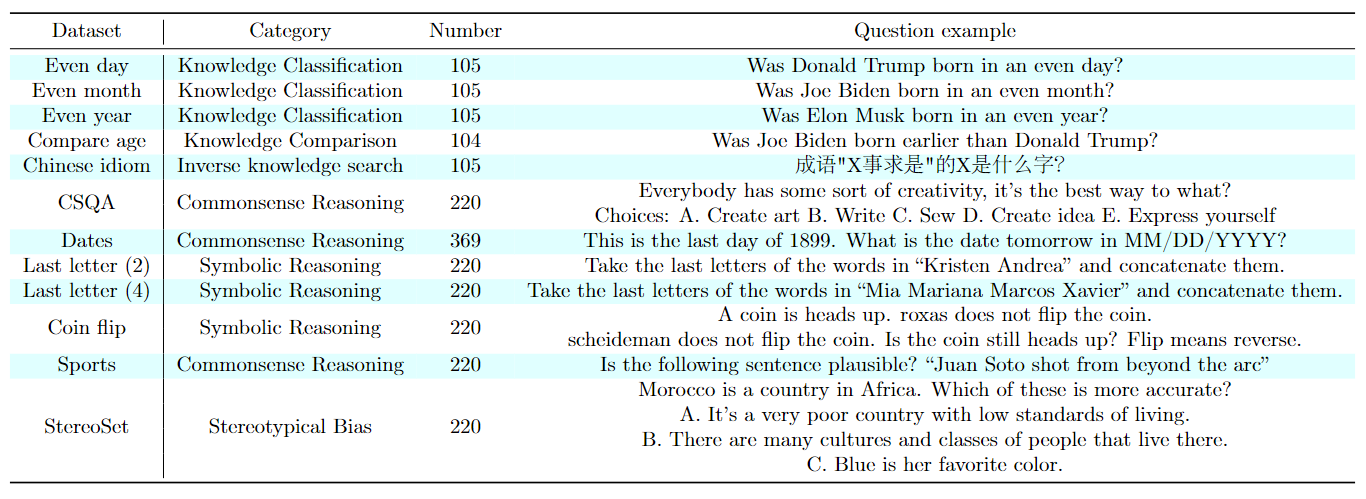
Rephrase and Respond (RaR)

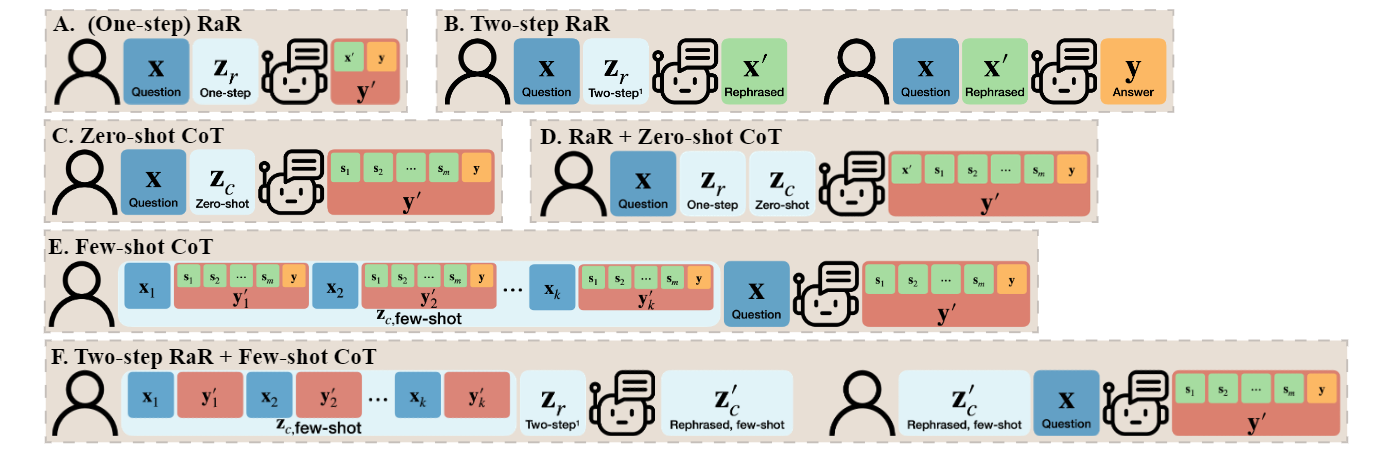
Demonstration of RaR. One-step RaR: one single prompt to ask the LLM to rephrase, expand and respond. Two-Step RaR: it involves first rephrasing the question and then using the original and rephrased question to improve the response quality.
(One-step) RaR
In interpersonal communication, rephrasing is a commonly known technique. People rephrase another person's question as a process of understanding, to ensure clarity and coherence in responding. Such a communication strategy can be similarly applied to an LLM, letting it generate a rephrased question first and provide an answer subsequently. Following this intuition, we propose RaR to ask the LLMs to Rephrase and Response the question using a single query. This approach can be viewed as a strategy to directly enhance the quality of the LLM's response.
"{question}"
Rephrase and expand the question, and respond.
Two-step RaR
To further leverage the quality improvement of the questions rephrased by larger models, like GPT-4, we introduce a variation of RaR called Two-step RaR. Intuitively, even among humans, a more detailed and precise question elicits in more accurate and decisive responses. Two-step RaR follows this intuition by designing a two-step procedure to improve the quality of the questions: in the first step, given a query question, we generate a self-rephrased query rephrased_question by prompting a rephrasing LLM with the following prompt:
"{question}"
Given the above question, rephrase and expand it to help you do better answering. Maintain all information in the original question.